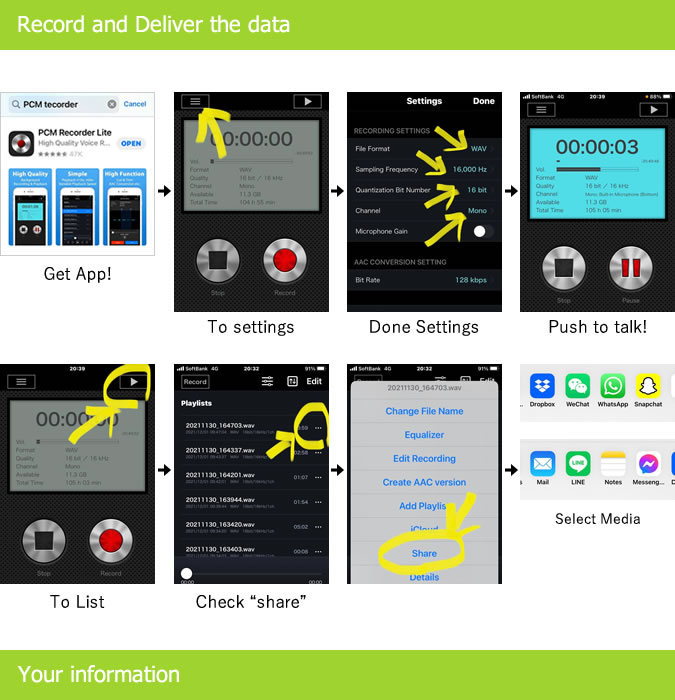
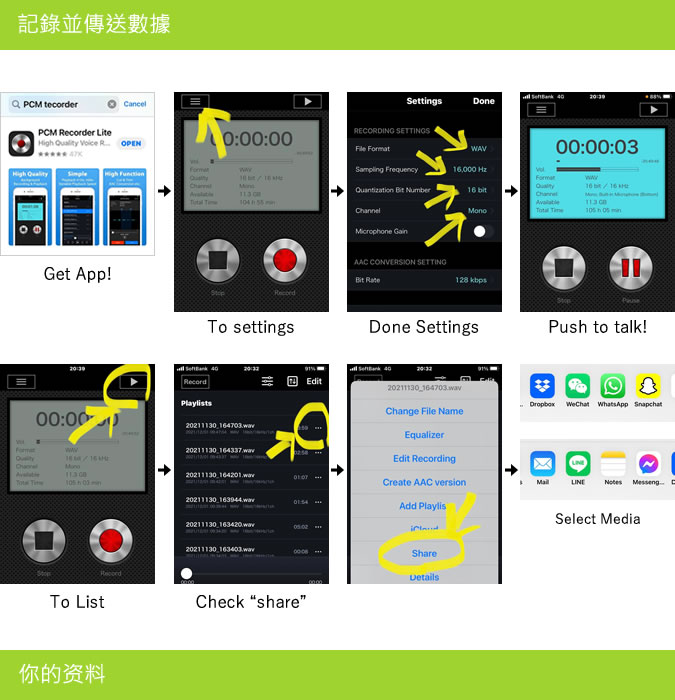
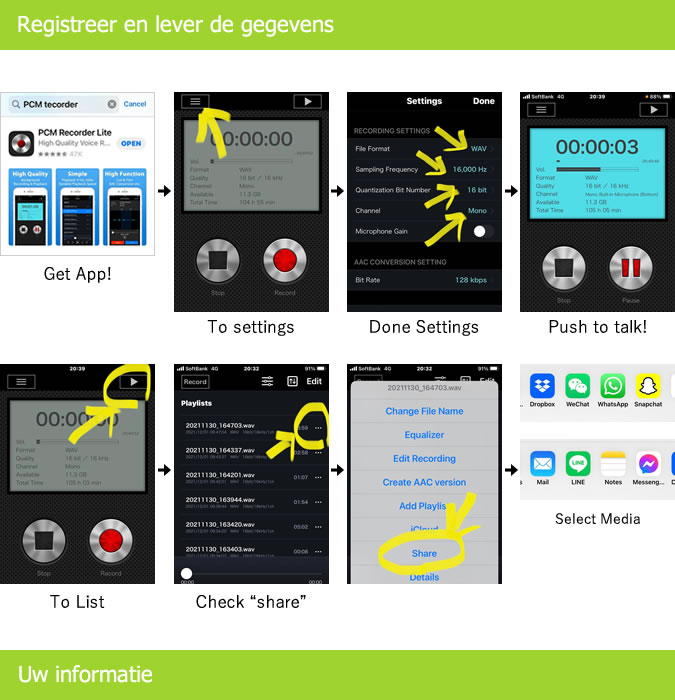
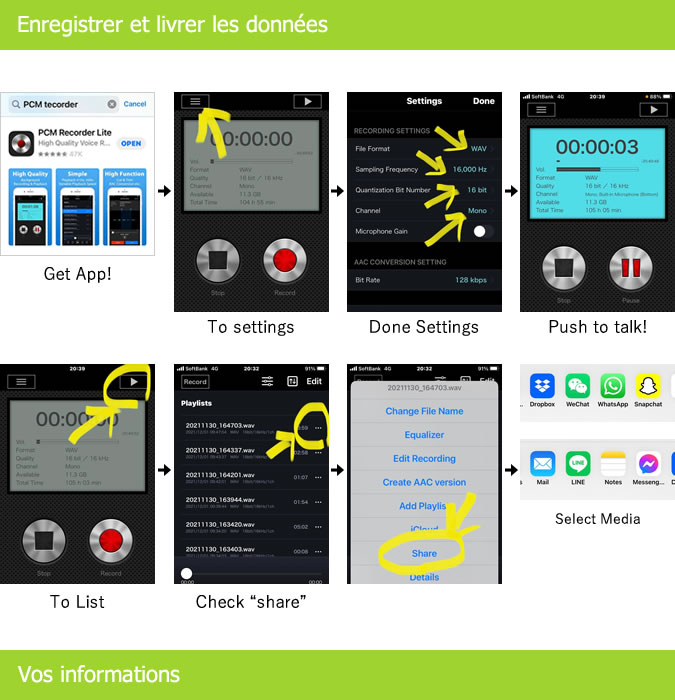
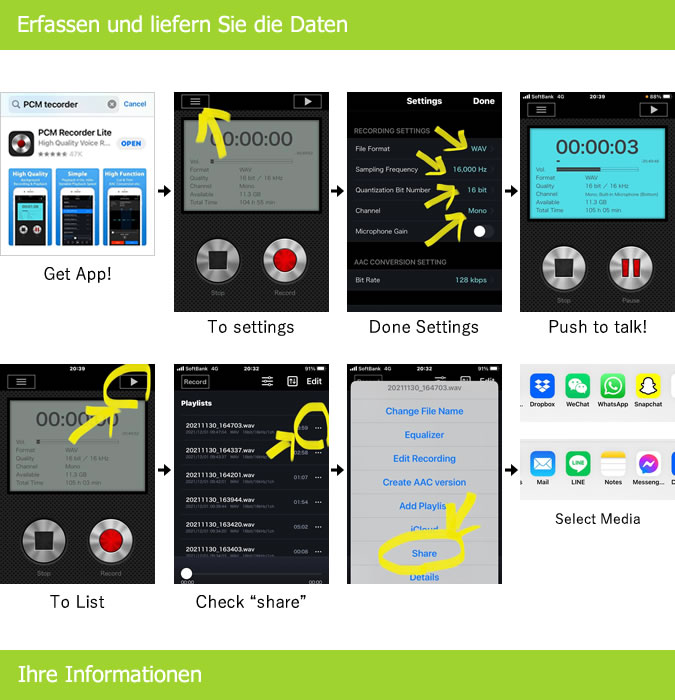
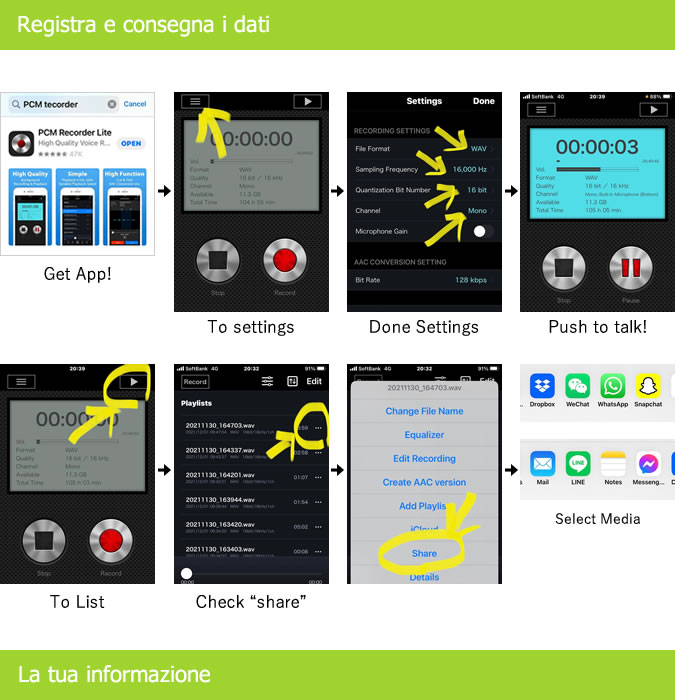
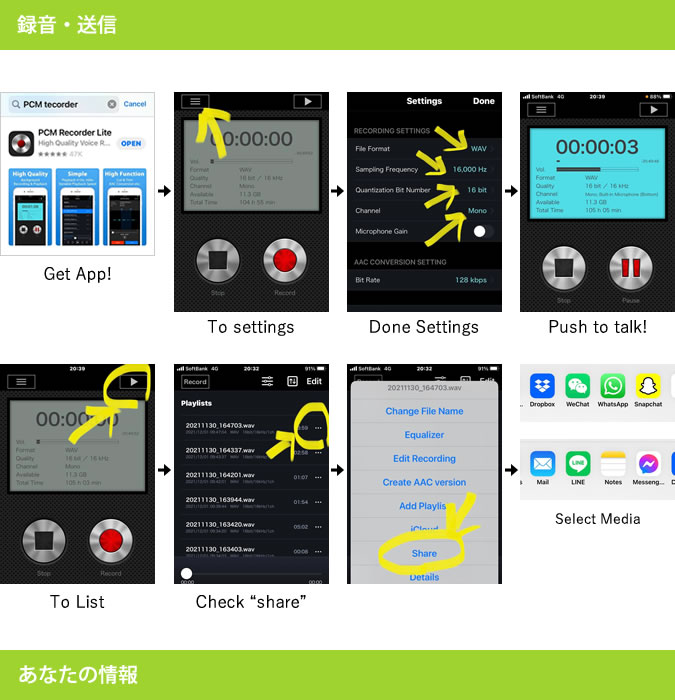
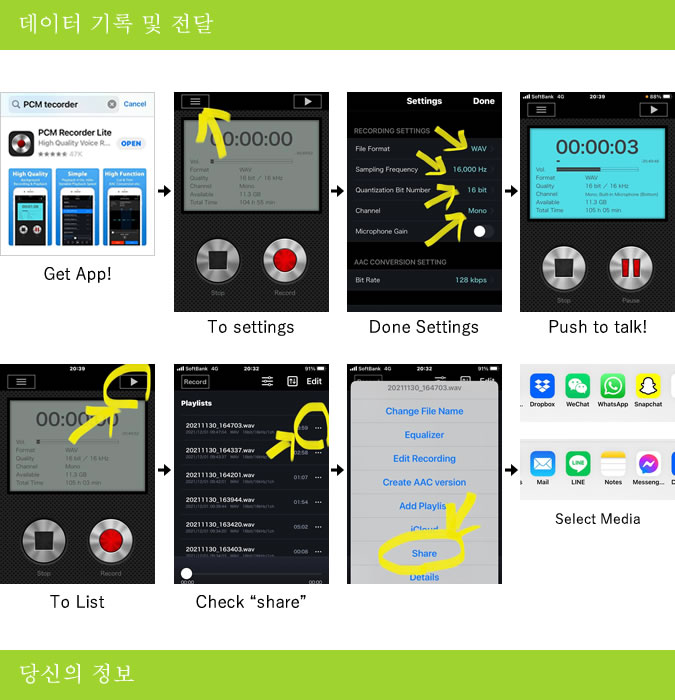
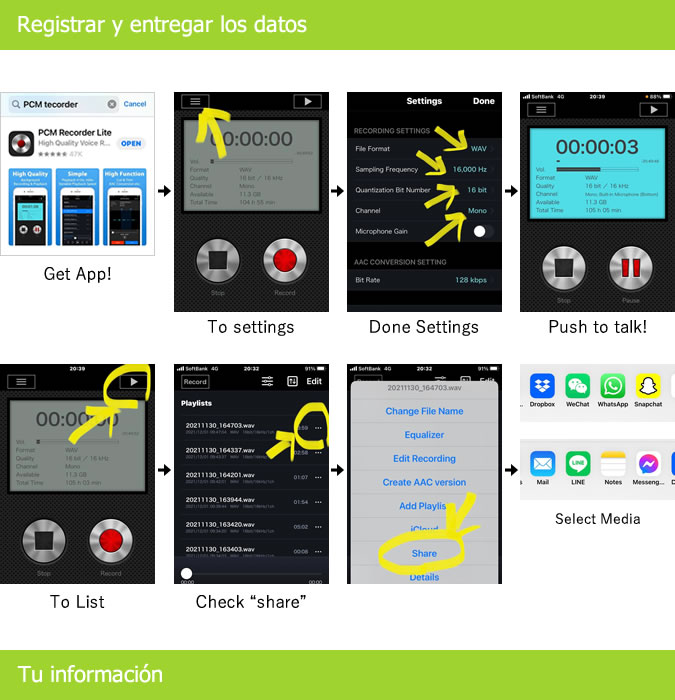
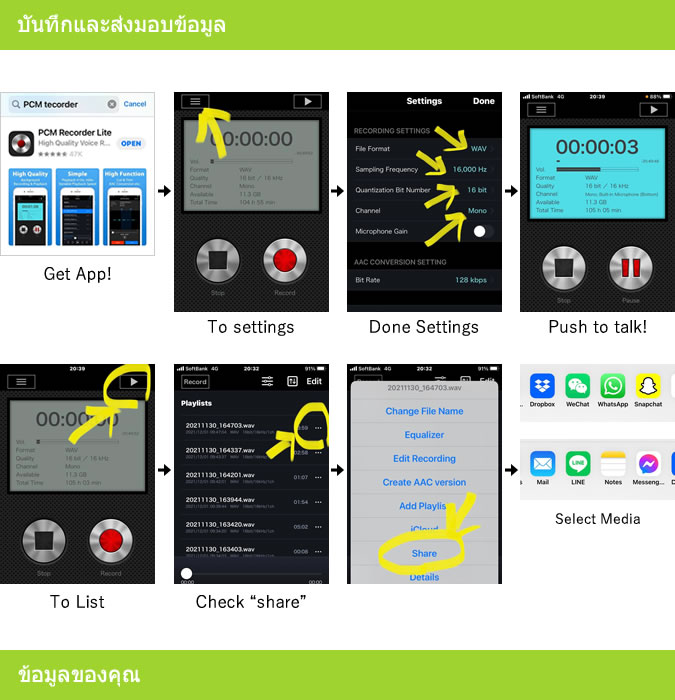
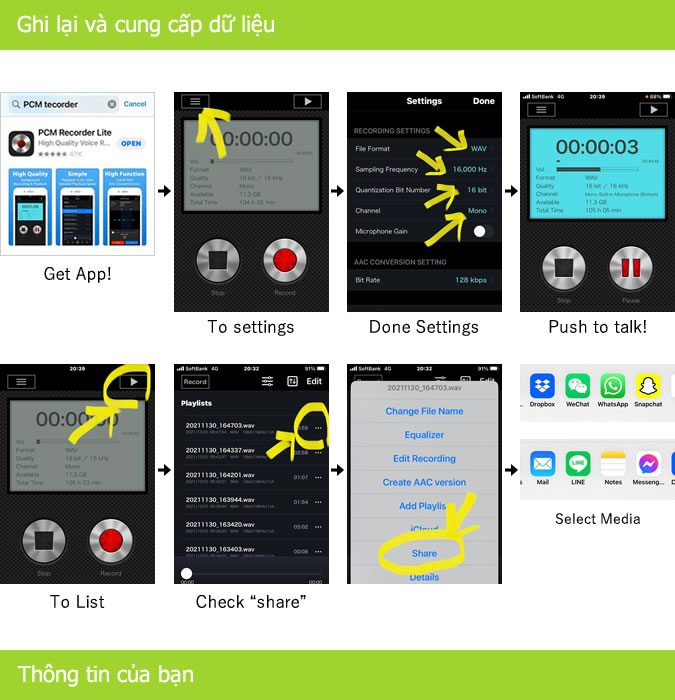
【録音話者同意】
Before the recording:
Thank you for coming today. We would like to explain about today's task to you.
The purpose of today's work is research and development for AI. I think you've heard the word AI. A computer with human-like intelligence. However, there are many types of AI. Recently famous are AI that can drive automatically and AI that can play chess. Autonomous driving is already possible, and AI that beats human professionals in chess is also possible. However, on the other hand, there is a field of AI that has not been completed yet and is said to be difficult in the future. It's communication AI. Certainly, AI that recognizes and translates words and short phrases has been completed to some extent. However, AI that can do a completely natural dialogue with humans has not been created. It is said to be extremely difficult in the future. However, although difficult, we are working on AI research and development in this field.
As you may know, AI today can "recognize" something in a field by learning a lot of data in that field. This process is called deep learning.For example, if you show hundreds of millions of pictures of cats and dogs with different appearances to a computer to learn, the computer can determine whether it is a cat or a dog even if the computer see the pictures of cats or dogs for the first time. It is said that computers can more accurately estimate the age of a person than humans whose image it sees for the first time.Therefore, also
when developing communication AI, it is necessary to let the computer learn "a large amount of data".
The large amount of data is "speech data-that is, a large amount of voice data". But there are many different languages ??around the world. Even in the same language, there are differences in accents depending on the dialect, region and age group. Furthermore, even if the same person utters the same word 10 times on the spot, the voice itself will be different 10 times. Therefore, it is necessary to have many people around the world speak a lot and record it. As mentioned above, this data is needed in large quantities, and we have recorded the voice data of hundreds of thousands of people around the world over the last 30-40 years. Still, communication AI has not been completed yet. It is difficult to develop AI and robots that can talk spontaneously. Today, as one of the millions of people around the world, I will record a data sample, your "voice," used for the research and development of AI in this difficult field (speech recognition).
Your voice recorded here today is used internally only for computer learning at Timehill Inc. and related companies, institute and universities. And your voice data is not open to the public.
Do you agree that your voice and speech recorded today/here will be used for the purposes mentioned above?
録音の前に:
本日は、株式会社タイムヒルの業務にお越しいただき、誠にありがとうございます。本日の業務について少しご説明致します。
本日の業務の目的は、AIの研究と開発です。AIという言葉を皆さんは聞かれたことがあると思います。人間のような知能を持つコンピュータのことです。しかしながら、そのAIには、さまざまな種類があります。最近で有名なのは、自動運転のできるAIや、将棋やチェスのできるAIですね。自動運転は既に可能となっていて、将棋やチェスで人間のプロに勝つAIもできてますよね。しかし一方で、未だできておらず、将来的にも困難と言われるAIの分野があります。それはコミュニケーションAIです。確かに、単語や短いフレーズの言葉を認識したり翻訳したり、と言ったAIは、ある程度出来上がっています。しかし、完全に人間と自然な対話のできるAIはできていません。将来的にも極めて困難と言われています。しかし、困難ながらも、我々はこの分野のAIの研究開発に取り組んでいます。
ご存知かも知れませんが、現在のAIは、ある分野のデータを「大量に学習」する事によって、その分野の「認識」ができるようになります。このプロセスをディープラーニング(日本語で深層学習)と言います。
例えば、異なる外見のネコと犬の写真を、それぞれ何億枚もコンピュータに見せて学習させると、初めて見るネコか犬の写真を見ても、コンピュータはそれが猫か犬かを判別することができます。初めて見る人の顔、外見からその人の年齢を推定する事は、コンピュータの方が人間より正確にできると言われています。従って、困難と言われるコミュニケーションAIの開発に当たっても「大量のデータ」をコンピュータに学習させる必要があります。
その大量のデータとは「話し言葉?すなわち音声の大量データ」の事です。しかし世界中には異なる言語がいっぱいあります。同じ言語でも方言や地域や年齢層によるアクセントの違いもあります。さらに同じ人間がその場で同じ言葉を10回発声しても、10回とも音声自体は異なります。従って、世界中の沢山の人達に沢山の言葉をしゃべってもらい、それを記録、録音していく工程が必要です。先に述べたように、このデータは大量に必要で、我々だけでも、この30-40年間で世界中で何十万人もの人の声(すなわち音声)を収録してきました。それでもまだまだコミュケーションAIは完成していません。それだけ普通に会話のできるAIやロボットは、開発が難しいという事ですね。今日は、その世界中の何百万人かの1人として、この難しいとされる言語と音声認識AIの研究開発に使用されるデータサンプル、つまりあなたの「声」を録音させていただきます。
今日ここでしゃべっていただき録音されたあなたの声は、株式会社タイムヒルとその関係あるAI研究開発企業や大学などでコンピュータに学習させるためだけに内部で使用され、一般に公開されたりするものではありません。
本日ここで録音されたあなたの声や言葉が、以上のような目的で使用されることに、あなたは同意しますか?